이 논문은 Federated learning과 domain generalization을 합친 느낌입니다.
Federated learning(FL)은 privacy를 지켜줄 수 있는 방법입니다.
서버에서 최근 모델을 불러와서, local client들이 자신들의 데이터로 모델을 학습합니다.
그 후에 서버에서는 client들의 파라미터 값을 합쳐서 모델을 업데이트합니다.
1. Introduction
기존 FL은 internal client에서 성능을 향상하는 것을 목적으로 합니다. 문제는 이렇게 하면 unseen domain에서 잘 작동을 하지 않습니다. 특히 medical에서는 scanner나 protocol이 다양하기 때문에 data distribution이 꽤 다를 수 있어서 문제가 됩니다.
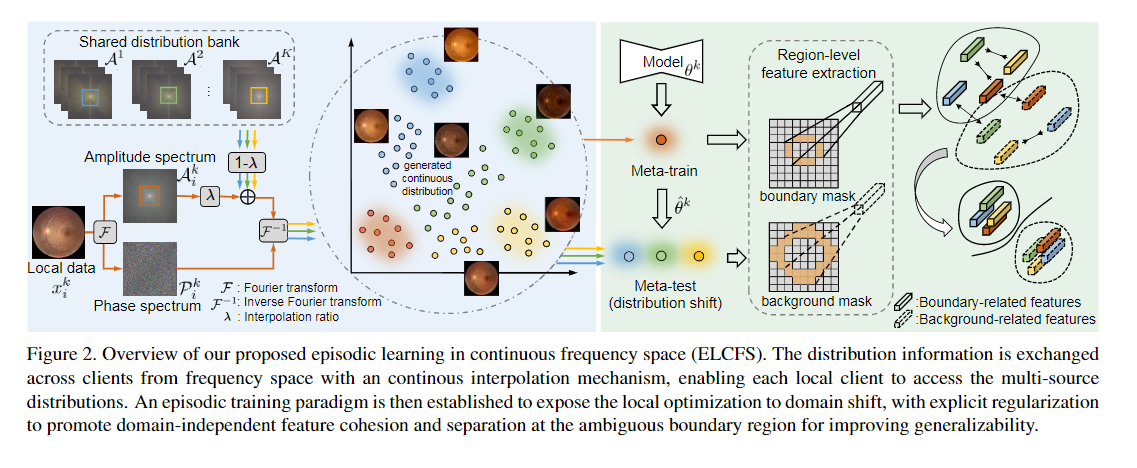
이 논문은 각 클라이언트들이 privacy를 지키면서 다른 클라이언트의 data distribution에 접근할 수 있도록 합니다. 그러기 위해서 이미지를 frequency space로 바꾼 후에, amplitude와 phase를 이용합니다.
2. Method
2.1 Federated Domain Generalization
K 개의 client들은 서버에서 global model의 파라미터를 받습니다. 그리고 각자의 local data를 이용하여 E epoch동안 모델의 파라미터를 업데이트합니다. 서버는 모든 클라이언트로부터 파라미터를 받고, 이들을 합쳐서 global model을 업데이트합니다.

합칠 때는 데이터의 개수가 더 많은 것에 가중치를 많이 주어서 업데이트합니다. N은 데이터의 개수입니다.
하지만 이 알고리즘에는 문제가 있습니다.
1. 클라이언트들은 각각 자신만의 데이터들로 학습을 했기 때문에, generalizable parameter를 배울 수가 없습니다.
2. 다른 clinical site로부터 얻은 medical image는 큰 이질성이 있습니다. 그래서 invariance한 것을 얻기 힘듭니다.
3. medical anatomises(해부학)의 구조는 꽤 모호한 boundary가 나타납니다. 이러한 문제에서는 domain invariance 한 것을 찾기 힘들다고 합니다.
2.2 Continuous Frequency Space Interpolation
흩어진 데이터의 한계점을 해결하기 위해서, 클라이언트끼리 data distribution을 서로 주고 받습니다. 하지만 privacy 때문에 raw data를 직접 주고받는 것은 금지되어 있기 때문에, frequency space의 정보를 이용하자고 저자들은 제안합니다.
frequency space로 이동하기 위해서 푸리에 변환을 이용합니다.

frequency space의 signal은 ampiltude(A) 와 phase(P)로 나눌 수 있습니다. amplitude는 low-level distribution(style)을, phase는 high-level semantics(object)를 가지고 있습니다. 서로 distribution information을 교환하기 위해서 A를 저장하는 bank를 만듭니다.
그 다음으로는 다른 도메인의 distiribution information을 local client로 주기 위해서, bank에서 랜덤으로 하나 선택해서, 그 amplitude의 low frequency로 바꿔줍니다. phase는 semantic 정보를 유지시켜주기 때문에, phase는 바꾸면 안 됩니다.

A_k와 A_n을 서로 섞어 줍니다. M은 low frequency에서는 1이고, 아닌 곳에서는 0입니다. local client의 data는 k입니다. 다른 client의 데이터는 n입니다. 람다는 [0.0, 1.0]에서 랜덤으로 뽑습니다.

이미지는 섞은 amplitude와 local client의 phase를 통해서 다시 이미지로 바꿉니다.
2.3 Boundary-oriented Episodic Learning
Episodic learning at local client
여기서 episodic learning을 이용합니다. raw input인 x를 meta-train, frequency odmain을 ㅗ부터 만들어진 t는 meta-test로 합니다.
우선 meta-trian으로 L seg(dice loss)를 최소화하는 방향으로 학습합니다.

그리고 meta-test로 L meta를 최소화하는 방향으로 학습하게 됩니다.
Boundary-oriented meta optimization
위에서 언급했다시피, anatomy의 애매한 boundary 때문에 다른 domain의 데이터에서는 잘 안됩니다. 이를 해결하기 위해서, boundary-related feature와 background-related feature의 cluster가 겹치지 않으면서 domain에 상관없이 잘 되도록 regularize를 해줍니다.
이 점이 왜 중요하나면 boundary의 근처의 feature를 잘 뽑아내지 못하면, distribution-independent 하고 class-specific하지 않게 됩니다.
우선 boundary-related하고 background-related 한 feature를 뽑아냅니다.
이는 ndimage.binary_erosion, ndimage.binary_dilation을 이용하여 뽑아냅니다.
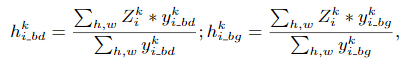
z는 feature이고, i_bd는 boundary, i_bg는 background입니다. 이 식을 이용하여 각 feature의 평균을 구해줍니다.

이를 infoNCE를 통해 같은 class의 cluster는 서로 밀접하도록 하고 다른 class는 멀리 떨어트립니다. p는 positive, 즉 같은 class를 의미하고, m은 무작위 anchor입니다. F는 쌍이 negative pair라면 1을, 아니면 0을 반환하도록 합니다.
동그라미 두 개는 cosine similarity입니다. k가 2인 이유는 (boundary, background) * k(client 수) 이기 때문입니다.
타우는 temperature로 hyper parameter입니다.
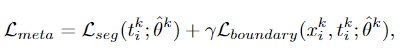
앞에서 meta-train 데이터셋으로 구한 파라미터를 이용하여 meta loss를 계산합니다. t는 meta-test 데이터입니다.
최종으로 이렇게 학습을 하게 됩니다.
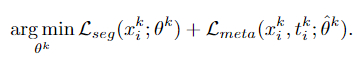
3. Experiment
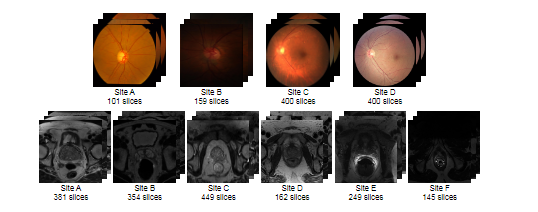
데이터 셋은 2가지 이용합니다. 각 데이터 셋은 다양한 domain의 데이터로 구성되어 있습니다.
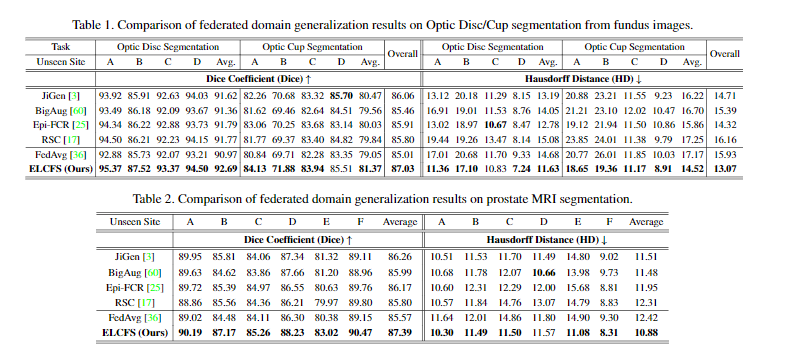
FedAvg는 각 클라이언트를 학습한 후에, 단순하게 평균을 내준 것 입니다.
위의 4가지는 DG방법입니다. jigen은 jigsaw를 이용한 방법이고, Epi-FCR은 episodic learning을 이용한 방법입니다. RSC는 기울기가 높은 것을 점차 마스킹하면서 다른 부분을 찾게 하는 방법입니다. BigAug는 제가 잘 모르겠네요...
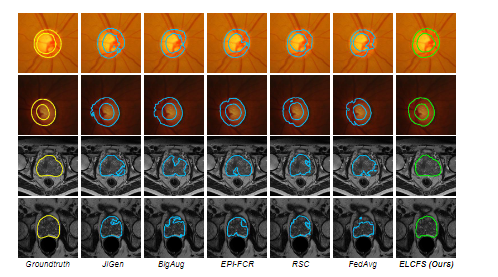
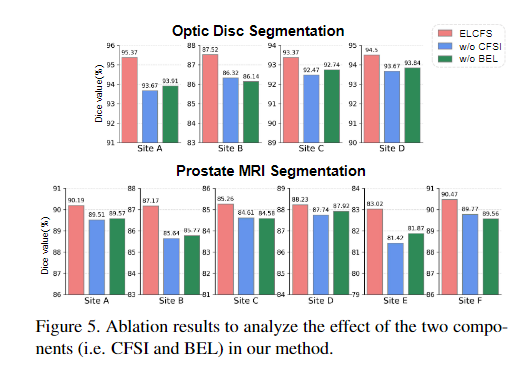
CFSI는 fouriere를 이용한 방법, BEL은 episodic learning을 이용한 방법입니다. 모두 사용했을 때가 성능이 제일 좋습니다. 둘 다 사용하지 않은 것보다 하나를 이용했을 경우가 1~2퍼센트 정도 성능이 오릅니다.
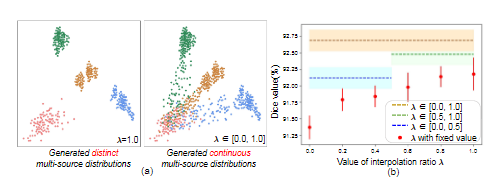
이는 amplitude를 어떻게 섞느냐에 대한 해석입니다. fix value로 하게 되면, 다양한 domain이 나오지 않지만, uniform distribution인 [0,1]에서 무작위 하게 뽑으면, 다양한 domain이 나오게 됩니다.
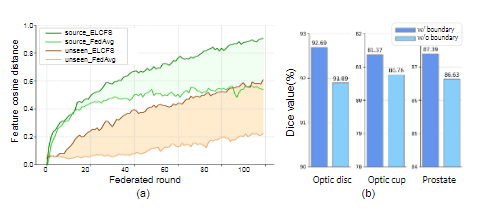
이는 boundary와 backgroud간의 distance를 계산한 것입니다. source domain에서 이 논문의 방법이 평균을 한 것보다 확실히 distance가 큽니다. unseen domain에서도 더 큰 것을 확인할 수 있습니다.
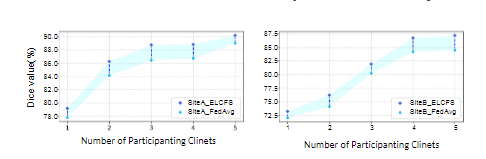
이는 client의 개수에 따른 성능입니다. 당연히 client가 많아지면, 데이터가 많아지기 때문에 성능은 오릅니다. 하지만 이 논문의 방법이 좀 더 성능이 좋은 것을 확인할 수 있습니다.



