1. Introduction
이 논문은 모델의 robustness를 키우기 위한 논문입니다. robustness를 키워서 out of domain에서 잘 작동을 하면, in domain에서의 성능이 어느 정도 떨어지는 점을 해결했습니다.
사람은 texture보다 shape을 중점으로 보는 것에 영감을 받아, shape-focused augmentation 방법을 제안합니다. texture bias를 줄일 뿐만이 아니라, shape bias에 더 집중을 할 수 있게끔 합니다.
2. Method

방법은 매우 간단합니다. original image에 각각 다른 augmentation 방법을 적용합니다. 그리고 segmentation model을 이용하여 foreground를 추출하고, 이를 이용하여 background와 foreground에 다른 augmentation 방법을 취하도록 할 수 있습니다.

매우 간단하죠.

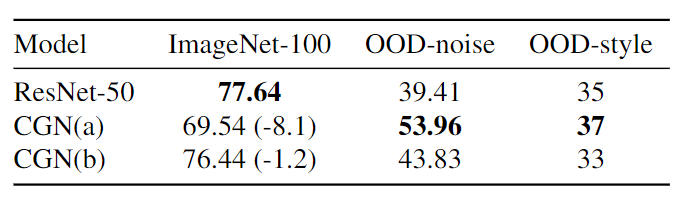
위 데이터를 통해서 하게 되면, in-domain에서의 성능은 떨어지게 되지만 robustness는 증가한 것을 확인할 수 있습니다.
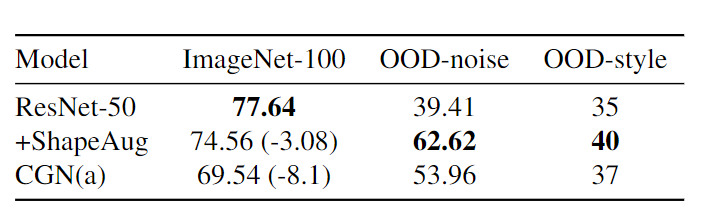
이 논문의 방법을 적용하면, in-domain에서 성능이 감소하기 하지만, 큰 폭으로 줄어듭니다. 그리고 robustness는 매우 좋아집니다.
CNN은 shape에 관한 정보를 바로 배울 수 없습니다. 이 방법들만 이용하면 단순한 data augmentation 입니다.
CNN이 shape에 대한 정보도 배울 수 있도록, contrastive learning 방법을 도입합니다.

무작위로 선정한 이미지 Anchor를 random resize crop이나 horizantal flip 해준 데이터를 positive로 합니다. 그리고 각각 shape-focused aug를 하고, 이들 간의 거리는 좁히고, 다른 클래스인 negative와는 멀리 떨어트리도록 학습을 하게 됩니다.
이 방법을 도입하면, shape 에 대한 common representation을 배울 수 있습니다.
좀 아쉬운 점은 negative에도 positive나 anchor와 똑같은 값으로 shape-focused augmentation을 하면 좀 더 shape에 집중할 수 있지 않을까라는 생각이 듭니다. texture가 흡사하고, foreground만 다르기 때문에 좀 더 성능이 올라갈 것 같은데, 궁금하네요.
3. Experiment


다른 논문의 contrastive learning 방법에 이 논문의 방법을 더하면, in-domain의 성능이 오히려 올라가고 robustness도 올라가는 것을 확인할 수 있습니다.

단순히 augmentation을 여러 번 하는 것으로 in-domain과 out-domain 간의 trade-off를 해결할 수 없다고 말합니다.
제가 작년에 생각했던 아이디어와 비슷한 논문이 CVPR에 accept 된 것을 보니 엄청 신기하네요. 작년에 연구할 때는 잘 안 되는 것 같아서 하다가 관뒀는데, 끝까지 해볼 걸 그랬네요.


