이번에는 두 대의 서버와 local kafka를 이용하여 실험해 본다.
kafka는 docker를 이용하여 실행한다.
producer
@Async
//항상 1 전송
public void prodcue1(String mm){
kafkaTemplate.send("fcm",Integer.toString(new Random().nextInt()), mm);
System.out.println(String.format("pro %s %s", mm, Thread.currentThread().getId()));
}
@Async
//항상 2 전송
public void produce2(String mm){
kafkaTemplate.send("fcm", Integer.toString(new Random().nextInt()), mm);
System.out.println(String.format("pro %s %s", mm, Thread.currentThread().getId()));
}
Consumer
//Server1
@KafkaListener(topics = "fcm", groupId = "fcm")
public void listen(ConsumerRecords<String, String> mm){
for(ConsumerRecord<String, String> c : mm) {
System.out.println(String.format("listen-1 partition : %s value : %s threadId :%s", c.partition(), c.value(),Thread.currentThread().getId()));
}
}
//Server2
@KafkaListener(topics = "fcm", groupId = "fcm")
public void listen(ConsumerRecords<String, String> mm){
for(ConsumerRecord<String, String> c : mm) {
System.out.println(String.format("listen-2 partition : %s value : %s threadId :%s", c.partition(), c.value(),Thread.currentThread().getId()));
}
}
우선 parition이 1개인 kafka와 서버 한 대를 이용하여 테스트한다.

당연하게도 server1의 하나의 consumer가 전부 읽는다.
다음에는 서버 한 개를 추가한다. consumer 설정은 위의 코드와 동일하다.

server1이다. 하나의 서버로 돌릴 때와 큰 차이가 없다.

server2에서는 consume이 안되는 것을 확인할 수 있다. 그 이유는 같은 그룹에서는 하나의 partition에 하나의 consumer만 접근할 수 있기 때문이다. 그룹이 partition에 대한 offset을 관리하기 때문에 이러한 현상이 일어난다.
다음에는 이 상태에서 터미널을 이용하여 kafka에 partition을 하나 추가한다.


이처럼 rebalancing이 일어난 것을 확인할 수 있다. 직접 kafka에 partition을 추가했을 뿐인데, 알아서 처리한다. 맨 마지막 줄을 주목하자.
결과는?

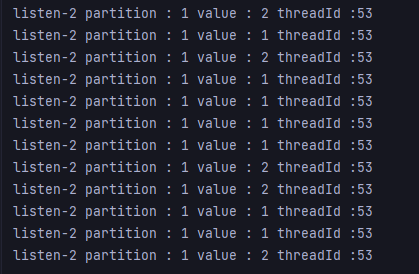
위에서 보다시피 server1에서는 partition 0에 관해서만 처리하고, server2에서는 1에 대해서만 처리한다.
갑자기 궁금해서 partition을 3개까지 늘려봤다.


보면 server1의 하나의 consumer가 2개의 partition에 대해서 처리하도록 바뀐 것을 확인할 수 있다. 이 rebalancing 되는 원리가 궁금하다. 나중에 시간이 되면 오픈소스를 확인해봐야겠다.
이번엔 server2를 종료시켜봤다.

rebalancing이 일어나고,
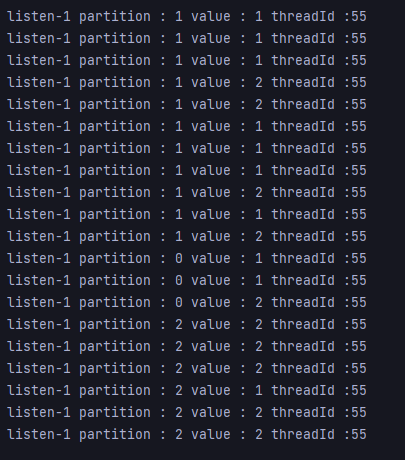
server1의 하나의 consumer가 전부 이를 처리한다.
다음에는 server2를 다시 작동시키고 그룹은 다른 그룹으로 변경한다. 현재 offset 읽는 option을 latest로 설정해서, 새로운 메시지를 읽지 않는다.
그래서 earliest로 바꾼 후에, 또 다른 그룹으로 바꾸고 실행해보았다.

이전에 넣은 메시지들을 전부 들고와서 처리하는 것을 확인할 수 있다. 그리고 모두 단일 thread로만 처리한다.
그리고 kafka에서 topic을 삭제했다. 그러면, consumer에서 계속 에러가 발생한다. offset을 읽을 수 없다고.
무한 루프도는 것처럼 계속 나와서 이에 대해서도 처리를 해줄 필요가 있을 것 같다.
그리고 producer를 이용해 메시지를 보내면, topic이 저절로 생긴다. 이는 kafka 내부 옵션으로 자동으로 생성되지 않도록할 수 있다.
앞에서는 concurrency설정을 1로 했을 경우이다.
이번에는 2로 설정해서 해본다.

partition이 하나이기 때문에, cocurrency를 2로 해도 차이가 없는 것을 확인할 수 있다.(하나의 partition에는 같은 그룹의 consumer 하나만)
partition을 하나 더 추가한다.

server1에서 두 개의 consumer를 이용하여 처리한다. 또한 consumer1(threadId 55)는 partition 0만, consumer2는 partition1만 처리한다.
또 partition을 하나 더 추가한다. 총 3개의 partition이 있다.
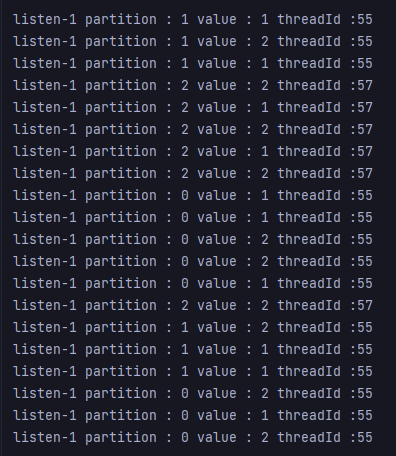
consumer는 2개만 작동하고, consumer1은 0,1을 처리하고 consumer2는 2를 처리하는 것을 확인할 수 있다.
다음에는 서버2의 concurrency는 1로 설정해서 실행해본다.

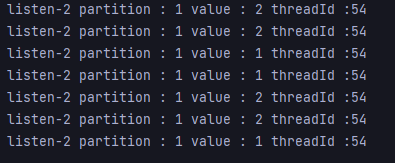
server2의 consumer에게 하나의 partition이 할당된 것을 확인할 수 있다.
server2의 concurrency를 2로 설정하고 다시 실행한다.




server1에서 consumer2가 놀게 되고, server2는 모두 작동하는 것을 확인할 수 있다.
여기서 server1의 consumer2가 자원을 얼마나 차지하는 지 궁금하다. 나중에 꼭 소스코드를 봐야겠다.
앞에서는 모두 producer에서 send할 때 key값을 랜덤하게 줬다. 그렇게 한 이유가 key 가 없이 하면, 다른 partition에 데이터가 들어가지 않아서 그렇게 했었다.
이에 대해서 조사해보니, producer의 partitioner기본 전략은 sticky 이다. sticky는 batch(byte)가 꽉 차면, 다른 partittion의 batch에 데이터를 쌓게 된다. 또한 linger.ms라는 것도 있는데, linger.ms를 넘어가면 자동으로 partition에 batch 데이터를 보낸다. linger.ms의 기본값은 0이고, batch는 조금 크다. 그래서 key없이 하면, 하나의 partition에만 데이터가 들어갔었다.
그래서 key부분을 지우고, produce1의 batch가 1이 되면 바로 전송하도록 수정하고 실행해봤다. 이는 하나의 서버에 두 개의 method를 만들어서 실행한다.
@Async
//항상 1전송
public void prodcue1(String mm){
kafkaTemplate.send("fcm", mm);
System.out.println(String.format("pro %s %s", mm, Thread.currentThread().getId()));
}
@Async
//항상 2전송
public void produce2(String mm){
kafkaTemplate2.send("fcm", mm);
System.out.println(String.format("pro %s %s", mm, Thread.currentThread().getId()));
}
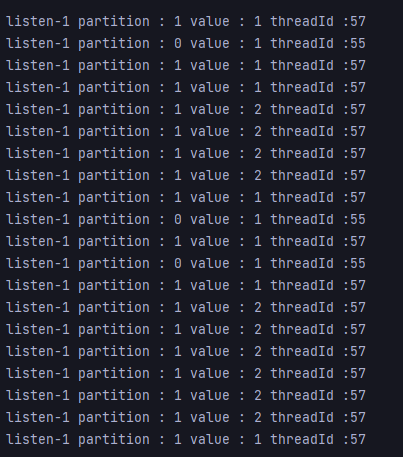
결과를 보면, 2가 partition 0에는 들어가지 않는 것을 확인할 수 있다. 이는 produce2의 batch가 크기 때문에 partition 1에만 계속 2를 넣는다. partition 0에 2를 넣고 싶어도, batch가 차기 전에 보내버리기 때문에 다음 partition의 batch에 데이터를 넣을 수 없다.
하지만 1은 partition 0,1 두 곳 모두에서 존재하는 것을 확인할 수 있다.
* 혼자 블로그나 공식 문서를 보고 공부하는 것이기 때문에 틀리는 것이 있을 수도 있습니다.
'BackEnd > Kafka' 카테고리의 다른 글
| [Kafka] TCP로 인한 대규모 Kafka 클러스터 요청 지연 문제 해결 사례 정리(라인 유튜브) (1) | 2023.10.10 |
|---|---|
| [Kafka] partition, consumer, producer 관계 (1) (0) | 2023.02.08 |
