1. Abstract
기존의 DANN처럼 adversarial learning을 이용하여 feature를 학습하면, feature는 invariant marginal distribution을 가집니다. 새로운 도메인에서 예측할 때에는 conditional distribution의 invariance가 더 중요하다고 합니다.
기존의 방법들은 marginal distribution P(X)가 변한다고 합니다. 반면, P(Y|X)는 전체 도메인에 걸쳐서 안정적으로 유지된다고 합니다. 제가 이해한 바로는 기존의 방법들은 feature의 표현에만 중점을 뒀다면, 이 논문은 feature와 label의 관계에 중점을 둔 것 같습니다.
2. Method

기본 clssification에 관련된 loss입니다. cross entropy 함수를 이용하는 것을 알 수 있습니다. F(x)는 feature이고, T는 classifier 하나, K는 전체 도메인 입니다. Q는 predicted label dstribution이라고 합니다. 이 수식만 이용하면, domain-invariant한 feature는 학습을 못합니다.

그렇기 때문에, GAN처럼 adversarial learning방법을 도입합니다. D는 domain discriminator입니다. minmax game에서 F와 D가 서로 반대되어야 할 것 같은데, 잘 이해가 안 가네요...
이는 P1(F(x)) = P2(F(x)) = ... = PK(F(x)) 같은 invariant marginal distribution을 구한다고 합니다. 이는 model의 generalization 성능을저하시킬 수 있습니다.

T' 은 각 도메인의 classifier를 의미합니다. 이 수식이 왜 도입되는 지는 제가 잘 이해를 못했습니다...
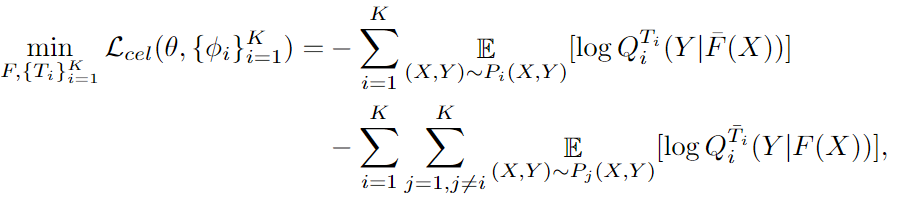
위에 -의 의미는 파라미터를 고정시켜 둔 것 입니다. adv Loss를 보면, class에 관한 정보가 빠져있습니다. class에 관한 정보도 배우도록 해준다고 합니다. 또 domain 마다 classifier를 추가합니다.

최종 loss는 이와 같습니다.

Eq 10이 방금 loss입니다.
3. Experiment

다른 방법들이랑 비교해보면, 다른 domain이여도 서로 잘 뭉쳐있는 것을 확인할 수 있습니다.



