1. Introduction
기존 MAE 같은 경우에는 computational cost가 높고 pretraing-finetuning discrepancy를 유발한다고 합니다.
이를 해결하기 위해서 convolution block의 정보 누출을 막아주는 masked convolution을 적용합니다. 또한 multi-scale feature를 제공하기 때문에, object detection과 segmentation의 성능도 올라간다고 말합니다.
2. method

The Hybrid Convolution-transformer Encoder
encoder의 구조는 총 3개의 stage로 이루어져 있습니다. convolution block은 self-attention 대신, 5 x 5 depthwise convolution을 이용합니다. 여기서 depthwise convolution을 이용하는 이유는 CoAtNet의 구조를 참고한 것 같습니다. 코드를 보니 CoAtNet의 구조와 비슷하네요. 그리고 모든 stage 사이사이마다 stride 2 conv를 이용하여 downsampling을 해줍니다.
1,2 stage에서는 local 적인 정보를 보게 되고, stage 3에서는 global하게 보기 됩니다. 기존의 vit(swin 등)는 absolute position embbeding 대신 relative postion embedding이나 zero-padded conv를 이용하지만, stage 3의 input에 absolute position embbeding을 더하는 것이 성능이 좋다고 이야기 합니다. cls token은 제거합니다.
Block-wise Masking with Masked Convolution
stage 1에서 masking token을 적용하게 되면, stage 3의 patch에서 일부 정보가 보여질 수 있습니다. 그 이유는 앞에서 convolution을 하게 되면, masking된 지역 주변의 픽셀 정보는 남아있기 때문에 이런 말을 한 것 같습니다. 이를 해결하기 위해, 위 그림처럼 stage 3의 input token의 일정 비율을 masking하고 이를 upsample하는 방법을 이용한다고 합니다.
첫 2 stage의 5 x 5 dconv는 masked patch보다 receptive field가 크기 때문에, 정보가 유출된다고 합니다.(2배, 4배를 하기 때문에 5보다 작아서 그런 것 같은데, 사실 왜 큰지 잘 이해가 안 가네요. stage 2의 feature 1 pixel을 하나의 patch로 보지느 않을 것 같은데...) 이를 해결하기 위해 masked convolution을 적용한다고 합니다. 이 방법이 성능에 큰 영향을 끼쳤다고 합니다. 코드를 보면 단순히 mask(0,1)와 곱하는 것 같습니다.
The Multi-scale Decoder and Loss
multi-scale feature decoder에 줄 때는, 윗 그림의 파란 박스 부분을 보면 됩니다. 단순히 upsample하고 다 더 해줍니다.
3. ablation study

epoch을 클수록 성능이 좋다고 합니다.

앞에서 말한 masked conv의 영향이 매우 큰 것을 알 수 있습니다. 근데 block masking은 무엇인지 모르겠네요. 논문에 검색해봐도 저거 하나만 뜨네요.
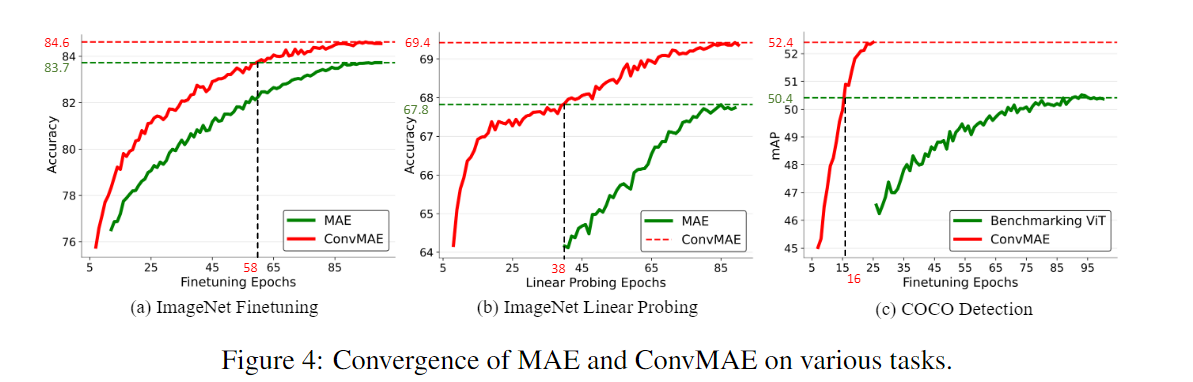
기존 mae보다 훨씬 빠르게 convergence하는 것을 확인할 수 있습니다.
'computer vision > self-supervised' 카테고리의 다른 글
| jigsaw puzzle 을 이용한 self-supervised (0) | 2022.07.20 |
|---|
