이번에 소개할 논문은 Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles 를 이용한 self-supervised 논문입니다.
1. Self-Supervised Learning of Pretext-Invariant Representations(CVPR 2020)

이 논문은 input image와 patch들을 서로 비슷하게 해주도록 하는 것이 목표입니다.

그렇게 해주기 위해서 nce loss를 이용합니다. I' 은 negative sample인데, 여기선 다른 이미지의 feature를 뜻 합니다.
s는 cosine similarity 입니다. Dn 은 데이터셋의 부분집합입니다.
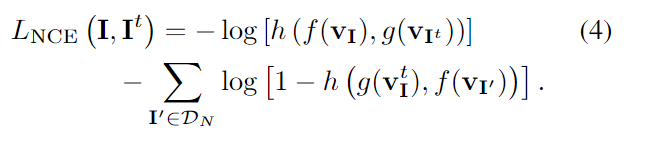
-log를 취해줌으로써 분모는 작게, 분자는 크게 해주도록 합니다. 즉, 다른 이미지와 이미지 patch들간의 유사도는 높이고, 다른 이미지와의 유사도는 낮춤으로써 이미지의 특징을 알 수 있습니다.

또한 negative sample을 뽑기 위해 memory bank를 이용합니다. 여기서 backbone은 resnet50을 이용합니다. res5는 backbone을 통해 나온 feature 2048 dim을 128로 줄어주는 역할(linear projection)을 합니다. patch들을 전부 concat해주고 다시 이를 128 차원이 나오도록 해줍니다. 128로 줄이면 계산 효율을 높일 수 있습니다. 메모리는 epoch 전에 ema 방법을 통해 업데이트 해줍니다.

최종 loss입니다. 첫번째 식은 위의 식과 동일하게 작동합니다. negative sample도 memory에 있는 것을 이용합니다.
두번째 식은 메모리와 이미지의 feature를 서로 비슷하게 해주고, 다른 이미지와는 다르게 해줍니다. 간단하면서도 기발한 아이디어인 것 같습니다.
2. Jigsaw Clustering for Unsupervised Visual Representation Learning(CVPR 2021)

이 방법은 다른 이미지의 patch와 서로 섞어줍니다. 섞은 이미지에서 해당 patch가 어느 이미지에 해당하는 지와 해당 patch가 이미지에서 몇 번째 patch인지 맞추도록 합니다.



이 식은 같은 클래스의 patch 간의 유사도는 높이고, 다른 class의 patch와의 유사도는 낮추도록 해줍니다.

L은 모델을 통해서 예측한 patch의 위치입니다.
Jigsaw puzzle을 이렇게 다양하게 이용하는 것을 보면, 되게 신기하네요. 이전 논문들을 참고하여 좀 더 좋은 아이디어를 생각하면 좋을 것 같습니다.
'computer vision > self-supervised' 카테고리의 다른 글
| ConvMAE: Masked Convolution Meets Masked Autoencoders(arxiv 2022) (0) | 2022.06.10 |
|---|
