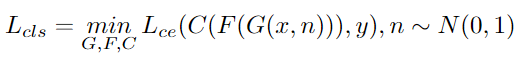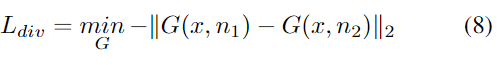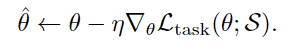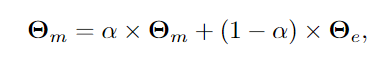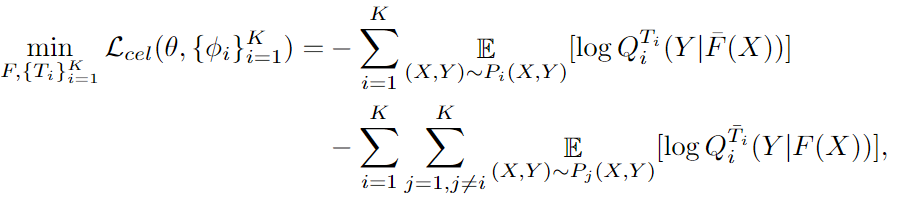1. Abstract
이 논문은 여러가지 normalization 기법을 이용하여 해결합니다. batch normalization(BN)은 도메인 이동이 큰 곳에서는 한계가 있습니다. 그렇기 때문에 domain specific style을 제거할 필요가 있습니다. 이를 하기 위해서 Instance normalization(IN)을 이용합니다.
2. Method

F는 feature extractor입니다.
normalization 파트를 제외한 나머지 parameter들은 domain끼리 서로 공유합니다.
D는 classifier입니다. 하나만 이용합니다.
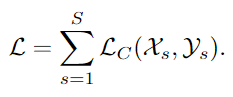
모든 도메인의 loss를 더해서 최종으로 학습하게 됩니다.
2.1 Instance Normalization for Domain Generalization
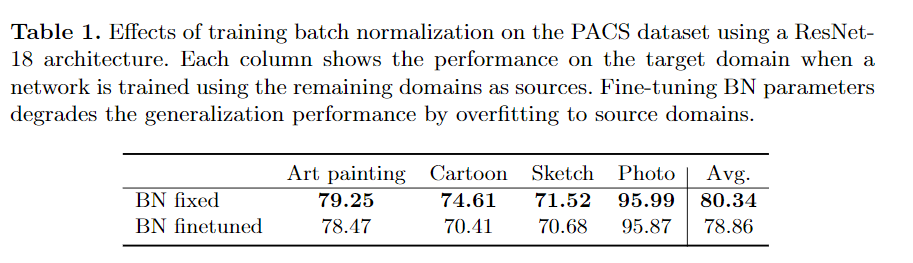
table1을 보면, BN은 cross domain 시나리오에서는 적절하지 않습니다. ImageNet으로 학습된 resnet을 PACS 데이터에 맞게끔 BN layer를 학습한 것이 아래결과입니다. 오히려 성능이 떨어지는 것을 확인할 수 있습니다.
이러한 문제를 해결하기 위해서 IN을 도입합니다. 이는 domain-agnostic 한 feature를 얻을 수 있다고 합니다.
IN은 sytle normalization하는 능력이 있기 때문에, style trasnfer에 주로 이용됩니다. AdaIN, MixStyle 등 다양한 곳에서 이를 활용했습니다. IN은 각 도메인의 style information을 줄여줍니다.

하지만 IN도 문제점이 있습니다. semantic한 정보가 많이 줄어들게 됩니다. 위 그림은 3가지 class에 대한 분포를 나타냅니다. a, b같은 경우에는 같은 class 끼리 잘 뭉쳐있습니다. 하지만 c는 그렇지 않습니다. inter-class varaince가 감소하게 되어서, 서로 잘 구분을 못합니다.
이 논문에서는 BN, IN 두 가지를 결합합니다.
2.2 Optimization for Domain-Specific Normalization
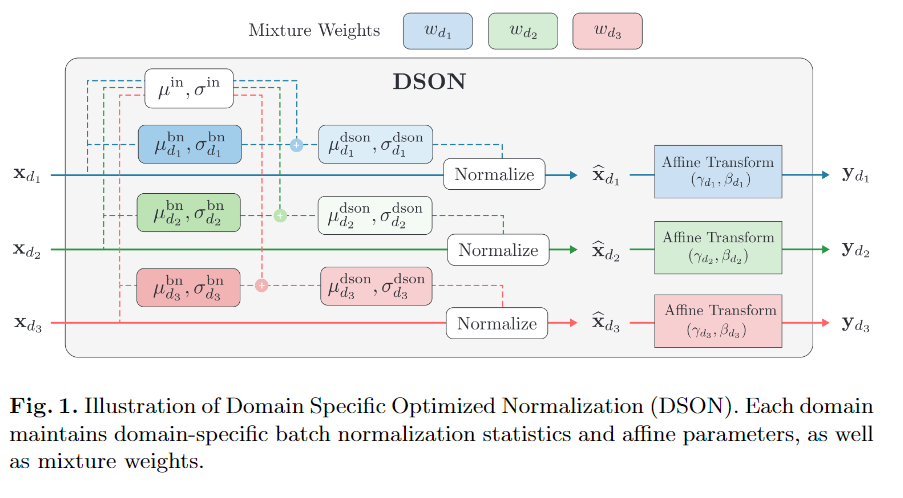
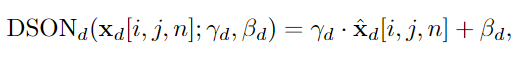

x는 각 채널에 대해서, H x W x N입니다. h는 세로, w는 가로, N은 batch입니다. 감마와 베타는 affine parameter입니다. 각 도메인마다 하나 씩 있습니다.
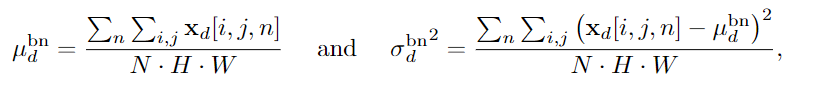
우선 BN에 이용되는 변수를 구합니다.

IN에 사용되는 변수도 구합니다. 식을 보면, IN의 평균은 B x C x 1 이런 형태인데, BN은 1 x C x 1 이런 모양입니다.
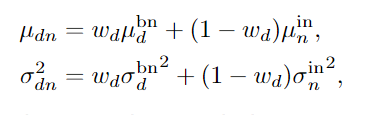
위해서 구한 것을 w만큼 서로 섞어줍니다. mixstyle의 수식이랑 조금 비슷한 모양인 것을 확인할 수 있습니다.
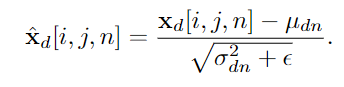
이렇게 normalization을 해준 후에, 맨 위의 식을 이용하여 affine translation을 해줍니다.
2.3 Inference
unseen domain에서는 나온 결과를 전부 평균을 내주고, softmax를 적용합니다.
3. Experiment
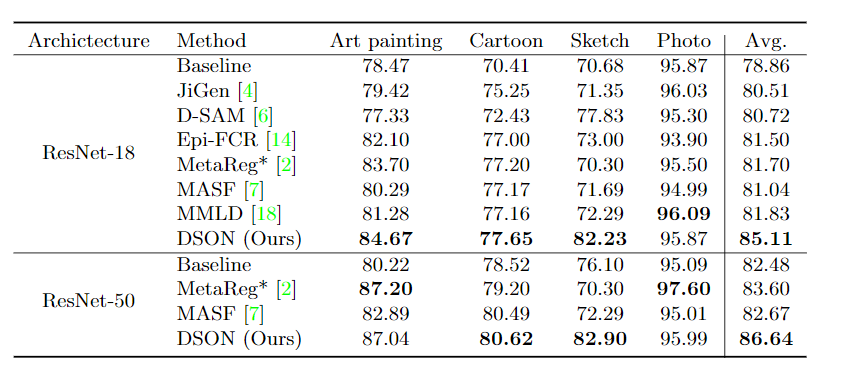
이 논문은 접근방법이 되게 신기해서 인상깊네요.