restart 했던 broker의 response time은 정상이였지만, producer의 request latency가 거의 16초나 되었다고 함.
왜 이런 현상이 나타났을까?
그렇다면 request는 어떠한 과정으로 일어나는 지?
producer -> broker -> producer 이런 식으로 latency를 측정함.
broker는 데이터를 완전히 받는 직후부터 시간을 측정함.
broker를 restart 했을 때, node_netstat_TcpExt_SyncookiesSent가 spike였음(값이 높았음)
TCP SYN Cookies에 대해 알아야함.
이는 syn flloding을 막기 위해 이용하는 것임.
SYN flood attack 이란?
TCP 통신할 때, syn 만 보내고, SYN + ACK 을 무시함. 그러면 서버는 syn queue에 이 SYN을 보관하다가 다 차게 됨.
그러면 syn cookie를 이용하게 됨.
syn cookie는 SYN 패킷에 있는 정보들을 이는 SYN + ACK의 ISN(Initial Sequence Number)로 만들어서 클라이언트에게 보냄.(원래는 random 값) 클라이언트가 서버에게 ACK을 보내면, 이 ACK의 정보를 decoding해서 connection을 맺게 됨.
그럼 왜 SYN flood가 일어났는지?
broker를 restart하면, 이 broker에 접속했던 client들이 일단 다른 broker에 접근을 하게 됨. restar가 되면, client는 broker들에게 fail-over를 하게 됨. 그리고 본래 broker들에게 기존 client들이 접속하게 됨.
연결하려는 client가 많아져서 syn flood 가 일어남.
tcp window가 문제가 됨?
요약하면, tcp window는 receiver가 처리할 수 있는 만큼의 양만 달라고 하는 것.
만약 데이터가 들어오는 속도가 처리 속도보다 빠르다면 데이터가 유실될 수 있음.
tcp 옵션에 window scaling 라는 옵션이 있음. 이는 windowsize * (2^scaling) 값이 최종 window size가 됨.
이를 이용하는 이유는 기존 window size의 최대값이 16비트 밖에 되지 않아서 그럼.
하지만 SYN cookie의 seq number는 32bit임. window scaling factor를 이용하지 못하게 됨.
-> 이는 한 번에 보낼 수 있는 데이터의 양이 적어지고 이는 throughput을 감소시킴.
근데 linux는 tcp timestamp가 유효하면, 이를 이용해서 window scaling 을 내장하는 기능이 있음.
그리고 scaling factor가 없어진다고 해도, timeout이 일어나는지?
실제로 net.ipv4.tcp_syncookies 값을 2로 설정하고 테스트해봤다고 함.
-> 모든 connection을 syncookies를 이용하여 연결함.
window scaling이 유효해야 하는 상태에서 지연이 일어나고 있었음?(잘 모르겠음)
-> broker 의 response time은 정상이지만, producer는 그렇지 않았음.
producer는 ack을 계속 기다리고 있었음. window size(789)가 작아서 이러한 현상이 일어났다고 함
window scaling 값도 1이였음. 즉 실제 window size는 789 * 2 ^ 1 = 1578이였음.
최근 개발할 때, 직접 postman으로 테스트 하는 것보다는 테스트 코드를 작성해서 돌려봅니다.
간단하게 테스트해볼 것이 있어서 통합테스트를 했었는데, 계속 null pointer exception이 발생했었습니다.
이 부분이 문제되는 코드 입니다.
@Service
public class SimpleService {
public Integer add(Integer a, Integer b) {
return a+ b;
}
}
@RestController
@RequiredArgsConstructor
public class SimpleController {
private SimpleService simpleService;
@RequestMapping("/")
public Map<String, Integer> add(Integer a, Integer b) {
Map<String, Integer> response = new HashMap<>();
response.put("ret", simpleService.add(a,b));
return response;
}
}
SimpleService.add(...)에서 발생한 것을 알 수 있습니다. 이 부분에 bean이 주입이 되지 않아서 이러한 에러가 발생합니다.
이를 해결하려면 매우 간단합니다.
@Service
public class SimpleService {
public Integer add(Integer a, Integer b) {
return a+ b;
}
}
@RestController
@RequiredArgsConstructor
public class SimpleController {
//private SimpleService simpleService;
private final SimpleService simpleService; //버그 수정
@RequestMapping("/")
public Map<String, Integer> add(Integer a, Integer b) {
Map<String, Integer> response = new HashMap<>();
response.put("ret", simpleService.add(a,b));
return response;
}
}
이렇게 final만 붙이면 됩니다.
왜 이러한 에러가 발생했을까요?
lombok의 @RequiredArgsConstructor 때문입니다.
이 코드의 docs를 보면,
이런 식으로 final fields가 필요하다는 것을 알 수 있습니다. 아니면 @NonNull 같은 null을 허용하지 않도록 하면 됩니다.
변하는 부분은 따로 인터페이스(strategy)로 만들고, 변경되지 않는 부분은 클래스(context)로 만들어서 해결.
즉, 인터페이스에 역할을 위임함.
@Slf4j
public class ContextV1 {
//call()이 있음. 이를 구현해야함. 이는 인터페이스임.
private Strategy strategy;
public ContextV1(Strategy strategy) {
this.strategy = strategy;
}
public void execute() {
long startTime = System.currentTimeMillis();
strategy.call();
long endTime = System.currentTimeMillis();
long resultTime = endTime - startTime;
log.info("resultTime={}", resultTime);
}
}
Context는 Strategy 인터페이스에만 의지.
코드보면 그냥 스프링에서 의존성 주입하는 것과 같음.
전략 패턴은 인터페이스에만 의존하고 있음. 템플릿 메소드 패턴은 부모 클래스의 변경에 민감했었음.
익명 클래스를 람다로 변경할 수 있음.
(인터페이스의 메소드가 1개라면)
이 패턴은 선 조립, 후 실행 방식에서 유용.
(context와 strategy 조립 후, 실행함.)
단점은 조립 후에 전략을 변경하기가 어려움.
setter로 변경해도 되지만, 만약 context가 싱글톤이라면 동시성 문제가 발생하게 됨.
public class ContextV2 {
public void execute(Strategy strategy) {
long startTime = System.currentTimeMillis();
strategy.call();
long endTime = System.currentTimeMillis();
long resultTime = endTime - startTime;
log.info("resultTime={}", resultTime);
}
}
파라미터로 받아오면 됨. 멋진데?
원하는 전략을 줄 수 있음. 단점은 실행할 때마다 전략을 줘야 함.
템플릿 콜백 패턴
콜백은 다른 함수로 실행 가능한 코드를 넘겨주고, 호출한 메소드에서 이러한 코드를 실행함.
저 위에 있는 contextv2가 템플릿 콜백임.
ContextV2가 템플릿 역할이고, strategy가 콜백임.
(ContextV1은 아님)
이는 GOF 패턴이 아닌, 스프링에서 주로 이용하는 패턴임.
이러한 코드의 문제점은 콜백으로 넘겨주는 코드를 다 작성을 해야함.
→ 즉 원본 코드의 수정이 필요함. 이를 해결하기 위해 프록시 패턴 이용.
인터페이스 컨트롤러에는 @RequestParam 같은 어노테이션을 달아줘야 함. 없으면 가끔 인식 안된다고 함.
@SpringBootApplication에서 @Import를 이용하여 원하는 설정파일 직접 주입할 수 있음.
(BasePackages 범위 밖에 있어도 등록가능)
@Controller를 쓰면 자동으로 Component 스캔 대상이 되어버림.
→ 수동 빈 등록을 하고 싶다면 RequestMapping 사용.
프록시
클라이언트 → 프록시 → 서버
중간에서 간접적으로 프록시가 요청을 할 수 있음.
클라이언트가 기대한 것 외에 다른 부가기능을 수행할 수 있음.
클라이언트는 프록시를 통해 요청한 결과만 받으면 됨. 어떠한 부가 기능이 수행 되었는 지는 몰라도 됨.
주요 기능
접근 제어.
권한에 따른 접근 차단
캐싱
지연 로딩
부가 기능 추가
부가 기능 수행(로그를 남기는 등)
프록시 패턴은 접근 제어가 목적.
데코레이터 패턴은 새로운 기능 추가가 목적
e.g)
프록시 캐시처럼 활용하기?
interface Subject {
T call();
}
class target implments Subject{
Server server;
T call() {
server....()
}
}
class proxy implents Subject {
Subject target;
String cacheValue;
T call() {
if(cacheValue == null) {
cacheValue = target.call()
}
return cacheValue
}
}
이런 식으로도 활용할 수 있음.
디자인 패턴에서 중요한 것은 의도.
데코레이터와 프록시 구분 기준은 의도임.
그리고 레포지토리나 서비스 등 인터페이스로 이용하면, 위처럼 프록시 패턴을 도입할 수 있음.
프록시가 이 인터페이스(컨트롤러, 서비스 등)를 상속받고, 이 프록시 내부에 진짜 객체를 이용하여 사용자의 요청을 처리할 수 있음.
→ 이런 식으로 하면 기존의 코드 변경이 사라짐.
그 이유는 기존 구체 객체를 빈으로 주는 게 아닌, 프록시를 주면 됨.
그러면 프록시 객체에서 로그를 남긴 후, 실제 객체에게 요청을 처리해달라고 하면 됨. 매우 멋진 방법처럼 보임.
구체 클래스를 상속해서 해도 됨.
하지만 super()로 부모 클래스의 생성자를 호출해야함. 인자로 null로 줘도 됨.
→ 왜냐하면 부모 클래스의 기능을 사용하지 않기 때문에.
(실제 객체를 필드로 가지고 있고, 그 객체를 통해 기능을 수행하기 때문에 부모 클래스의 기능을 사용하는 것이 아님.)
그래서 보통 인터페이스 기반이 더 좋음. 상속의 제약에서 자유로움.
인터페이스의 단점은 해당 인터페이스가 필요하다는 것이 단점임. 테스팅할 때도 단점이 있다고 함. 하지만 변경이 거의 일어나지 않는다면 구체 클래스를 하는 것이 더 좋을 수도 있음. 또한 실무에서는 둘 다 섞인 경우도 있기 때문에 우선 둘 다 알아둬야 함.
프록시의 단점은 프록시 클래스를 너무 많이 만들어야 함.
만약 적용할 클래스가 많아지면, 프록시 클래스도 그 만큼 만들어줘야 함.
→ 동적 프록시가 이를 해결해줌.
동적 프록시
리플렉션을 이용하여 메소드를 동적으로 변경가능.
리플렉션으로 method 따로 분리할 수 있음.
그리고 이를 프록시 객체에 method 를 넘겨주면 됨.
method.invoke(target, args) 로 실행할 수 있음. target은 해당 메소드를 실행할 인스턴스. args는 넘길 인수.
InvocationHandler의 구현 객체도 필요함. 거기에 invoke를 오버라이딩 해야함
그리고 jdk 리플렉션에서 지원해주는 proxy가 있음. Proxy.newProxyInstance를 통해 동적인 프록시 객체를 만들어줌. 하지만 이는 인터페이스에 적용 가능.
하지만 리플렉션은 런타임에 작동하기 때문에, 컴파일 시점에 오류 못 잡음. 되도록 사용하면 안됨.
private static final String[] PATTERNS = {"request*", "order*", "save*"};
@Bean
public OrderServiceV1 orderServiceV1(LogTrace logTrace) {
OrderServiceV1 orderService = new OrderServiceV1Impl(orderRepositoryV1(logTrace));
OrderServiceV1 proxy = (OrderServiceV1)Proxy.newProxyInstance(
OrderServiceV1.class.getClassLoader(),
new Class[]{OrderServiceV1.class},
new LogTraceFilterHandler(orderService, logTrace, PATTERNS)
);
return proxy;
}
proxy가 빈으로 등록이 됨.
만약 인터페이스가 아닌 클래스에 적용하고 싶다면?
CGLIB(code generatpr library) 사용
이를 사용하는 경우는 거의 없음. 스프링에서 proxy factory라는 것을 제공해주기 때문.
이 안의 MethodInterceptor를 구현하면 됨.
그리고 Enhancer에 앞에서 구현한 것과 프록시를 적용할 객체를 넘겨주면 됨.
enhancer.create() 하면 프록시를 적용할 객체를 반환해줌.
하나는 클래스만, 하나는 인터페이스만 지원을 해줌.
→ 스프링에서 제공해주는 프록시 팩토리는 둘 다 이용가능.
스프링의 프록시 팩토리
프록시 팩토리는 Advice를 만들어서 처리를 하게 됨. CGLIB나 JDK 동적 프록시는 이러한 Advice를 호출하게 됨.
→ 즉, JDK, CGLIB 안에 코드를 따로따로 구현할 필요가 없음.
프록시 팩토리도 MethodInterceptor를 구현하면 됨(CGLIB와 다른 거임! 패키지 주의)
invociation.proceed() 하면 됨.
이전과 달리 target에 대한 정보가 안보임.
@Slf4j
public class TimeAdvice implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
log.info("TimeProxy 실행");
long startTime = System.currentTimeMillis();
...
}
이는 MethodInvocation invocation 내에 이미 들어있음.
이는 JDK가 기본임. 인터페이스가 없다면 CGLIB를 통해 동적프록시를 생성함.
이런 식으로 사용 가능
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvice(new TimeAdvice());
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
매우 간단해짐.
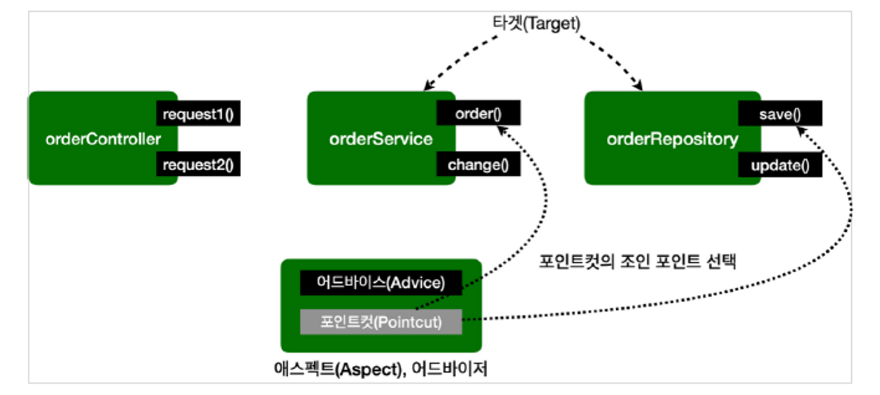
포인트컷(Pointcut)은 필터링 로직. 클래스와 메서드 이름으로 필터링 가능.
어드바이스(Advice)는 앞에서 본 것처럼 프록시가 호출하는 부가 기능.
어드바이저(Advisor)는 둘 다 가지고 있는 것.
여러 프록시를 사용하려면?
//clients -> proxy2 -> proxy1 -> server
DefaultPointcutAdvisor advisor2 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice2());
DefaultPointcutAdvisor advisor1 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice1());
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory1 = new ProxyFactory(target);
proxyFactory1.addAdvisor(advisor2);
proxyFactory1.addAdvisor(advisor1);
이는 프록시가 여러 개 생성되는 것이 아님!
proxy가 여러 advisor를 사용하는 것임. 하나의 프록시에 어려 어드바이저를 적용되는 것.
등록 순서도 중요함
하지만 프록시 패턴에도 문제가 있음.
Configuration에서 bean을 만들때 중복되는 코드가 많음. 모든 클래스의 프록시 설정 코드를 다 작성해줘야 함.
컴포넌트 스캔을 하면 프록시 적용이 불가능함.
이미 기존 객체가 빈으로 바로 주입이 되어버림. 이 대신 프록시를 주입 해주도록 설정 해야하는데….
이를 처리하기 위해 빈 후처리기 이용하면 됨.
빈 후처리기(BeanPostProcessor)
빈을 등록하기 전에 빈을 조작할 수 있음.
후 처리 작업 시에 객체를 다른 객체로 바꿔치기도 할 수 있음.
BeanPostProcessor 인터페이스를 구현해야함.
before 메소드는 @PostConstruct 발생하기 전.
after는 초기화되고 난 후.
자바 8 이후는 default 로 선언되어 있어서 override를 안해도 오류가 안 뜸.
@Slf4j
public class PackageLogTraceProxyPostProcessor implements BeanPostProcessor {
private final String basePackage;
private final Advisor advisor;
public PackageLogTraceProxyPostProcessor(String basePackage, Advisor advisor) {
this.basePackage = basePackage;
this.advisor = advisor;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
log.info("param beanName={} bean={}", beanName, bean.getClass());
//프록시 적용 대상 여부 체크
//프록시 적용 대상이 아니면 원본을 그대로 반환
String packageName = bean.getClass().getPackageName();
if (!packageName.startsWith(basePackage)) {
return bean;
}
//프록시 대상이면 프록시를 만들어서 반환
ProxyFactory proxyFactory = new ProxyFactory(bean);
proxyFactory.addAdvisor(advisor);
Object proxy = proxyFactory.getProxy();
log.info("create proxy: target={} proxy={}", bean.getClass(),
proxy.getClass());
return proxy;
}
}
AnnotationAwareAspectJAutoProxyCreator라는 빈 후처리기가 자동으로 등록이 됨?
(자동 프록시 생성기)
모든 Advisor 빈을 조회함. 이에 있는 포인트컷을 이용하여 해당 객체에 프록시를 적용할 지 결정함.
해당 객체의 모든 메서드를 포인트컷에 매칭해봄. 하나라도 만족하면, 프록시 대상이 됨.
위처럼 따로 PostProccesor를 구현안해도 됨. 그냥 Advisor만 빈으로 등록하면 됨.
→ 스프링이 알아서 프록시로 해줌.
근데 여러 advisor가 있다면 순서는 어떻게 적용이 되는지? → @Order로 선언을 해주면 되나.(이는 강의에는 없음. 뒤쪽에 나옴)
스프링이 자체로 내부에서 사용하는 bean에도 해당 패턴이 있으면 로그를 남기는 문제가 있음.
(orderController 같은 빈을 등록할 때도 로그가 남음. pattern에서 order라는 메소드가 들어가있으면, 전부 로그를 남기도록 했기 때문.)
AspectJExpressionPoincut으로 이를 해결가능함.
실무에서 이를 주로 이용한다고 함.
정규표현식으로 처리 가능.
(자세한 건 AOP 부분에서 설명 나오는 듯 함.)
만약 여러 개의 advisor를 등록 시, 하나의 adivsor의 포인트컷만 만족해도 프록시로 생성됨. 대신 프록시에 만족하는 advisor만 포함.
(그렇다면 조건마다 여러 프록시 객체가 만들어지는 것인가? 아니면 하나의 프록시에서 매번 포인트컷으로 필터링을 하는지)
Aspect 프록시
@Aspect 어노테이션으로 편리하기 프록시 생성가능.
@Aspect
public class LogTraceAspect {
...
//pointcut
@Around("execution(*hello.proxy.app..*(..))")
public Object method(ProceedingJoinPoint joinPoint) throws Throwable {
//joinPoint에 정보가 들어있음.(메소드)
//Advice 로직 작성하면 됨.
}
...
}
앞에서 본 AnnotationAwareAspectAutoProxyGenerator는 @Aspect의 Around부분을 Advisor로 변환하여 저장해줌.
순서 정하려면 @Order 사용하면 됨
@AOP(Aspect Oriented Programming)
애플리케이션은 핵심기능(비즈니스 로직?), 부가기능(트랜잭션, 로그 추적 등)으로 구분할 수 있음.
중복되는 부가 기능을 여러 클래스에 적용하려면?
→ 모든 클래스에 적용하기 위해 코드를 수정해주거나 유틸리티 클래스를 만들어서 적용시킴.
→ 이는 유지보수 하기 힘들고 구조가 복잡해짐.
이를 해결하기 위해 AOP가 나옴.
횡단 관심사를 깔끔하게 모듈화할 수 있음.
오류 검사 및 처리
동기화
성능 최적화(캐싱)
모니터링 및 로깅
어떤 방식으로 로직을 추가할 수 있나?
컴파일 시점(AspectJ 사용)
컴파일된 시점에 원본 로직에 부가 기능 로직이 추가됨. 위빙이라고 함.
단점은 특별한 컴파일러가 필요하고 복잡함.
클래스 로딩 시점(AspectJ 사용)
자바는 JVM에 내부의 클래스 로더에 .class 파일을 저장함.
이 시점에 aspect를 적용하는 것이 로드 타임 위빙임
로더 조작기를 지정해야 하는데, 번거롭고 운영하기 어려움.
런타임 시점(프록시, 지금까지 했던 것.)
DI, 프록시, 빈 포스트 프로세서 같은 것들을 동원해서 프록시를 통해 스프링 빈에 부가 기능을 추가함.
프록시를 사용하기 때문에 일부 제약이 있음. 메서드 호출에만 적용할 수가 있음.(생성자에는 안됨?)
실제 대상 코드는 그대로 유지가 됨. 항상 프록시를 통해서 조작함.
스프링 빈에만 적용이 가능함.
AspectJ는 사용하기 어려움.
스프링 AOP는 편리함. 그리고 실무에서는 이 기능만 이용해도 대부분의 문제를 해결할 수 있음.
AOP 용어
JoinPoint
어드바이스가 적용될수 있는 위치, 메소드 실행, 생성자 호출, 필드 값 접근, static 메서드 접근 같은 프로그램 실행 중 지점.
@Around("@annotation(retry)")
public Object doRetry(ProceedingJoinPoint joinPoint, Retry retry) throws Throwable
이런 식으로도 인자 받을 수 있음. 인자로 Retry retry가 있기 때문에 자동으로 해당 annotation에 대한 정보를 받아올 수 있음.
AOP 실무 유의점
aop를 적용하려면 항상 프록시를 통해 객체를 호출해야함.
문제는 대상 객체의 내부에서 메서드 호출이 발생하면, 프록시를 거치지 않고 대상 객체를 직접 호출함.(실무에서도 만날 수 있는 문제라고 하심)
@Slf4j
@Component
public class CallServiceV0 {
public void external() {
log.info("call external");
internal(); //내부 메서드 호출(this.internal()) 프록시를 거치지 않음.
}
public void internal() {
log.info("call internal");
}
}
@Slf4j
@Aspect
public class CallLogAspect {
@Before("execution(* hello.aop.internalcall..*.*(..))")
public void doLog(JoinPoint joinPoint) {
log.info("aop={}", joinPoint.getSignature());
}
}
1. //프록시 호출
2. CallLogAspect : aop=void hello.aop.internalcall.CallServiceV0.external()
3. CallServiceV0 : call external
4. CallServiceV0 : call internal
internal에는 프록시가 호출이 되지 않았음. 그 이유는 this.internal()을 호출하기 때문임.
proxy → target이 되는데 target에서 자신의 method를 호출함.
스프링 프록시의 한계임.
AspectJ는 이런 문제가 발생하지 않음. 그 이유는 실제 byte code를 조작해서 코드를 넣어버리기 때문에.
이를 해결하기 위해서 자기 자신을 주입하면 됨
@Slf4j
@Component
public class CallServiceV1 {
private CallServiceV1 callServiceV1;
//생성자로 하면 순환 참조를 하기 때문에 문제가 생김. 프록시가 먼저냐 이 bean이 먼저냐.
//그래서 setter로 주입을 함. 실무에서 신경쓰기 진짜 어려울 듯.
@Autowired
public void setCallServiceV1(CallServiceV1 callServiceV1) {
this.callServiceV1 = callServiceV1;
}
public void external() {
log.info("call external");
callServiceV1.internal(); //외부 메서드 호출
}
public void internal() {
log.info("call internal");
}
}
그 다음 해결책은 지연 조회
@Slf4j
@Component
@RequiredArgsConstructor
public class CallServiceV2 {
// private final ApplicationContext applicationContext;
//기본편 싱글톤에 프로로타입 주입할 때 봤던 것.
private final ObjectProvider<CallServiceV2> callServiceProvider;
public void external() {
log.info("call external");
// CallServiceV2 callServiceV2 =
applicationContext.getBean(CallServiceV2.class);
CallServiceV2 callServiceV2 = callServiceProvider.getObject();
callServiceV2.internal(); //외부 메서드 호출
}
public void internal() {
log.info("call internal");
}
}
ObjectProvider는 실제 객체를 사용할 때 빈을 찾아옴. 자기 자신을 주입받지 않음.
앞에서는 뭔가 어색함.
제일 좋은 방법은 내부 호출이 없도록 구조를 바꾸는 방법임. 스프링에서도 이 방법을 권장함.
@Slf4j
@Component
@RequiredArgsConstructor
public class CallServiceV3 {
private final InternalService internalService;
public void external() {
log.info("call external");
internalService.internal(); //외부 메서드 호출
}
}
@Slf4j
@Component
public class InternalService {
public void internal() {
log.info("call internal");
}
}
Callback의 문제점은 callback hell 입니다. callback 깊이가 깊어질수록 indent가 깊어져서 코드를 이해하기 어렵게 됩니다.
userService.getFavorites(userId, new Callback<List<String>>() { //callback inteface
//성공하면 이거 호출?
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
//리스트가 비었으면, 여기서 다른 서비스의 콜백 호출함.
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
//여기서도 다른 callback 호출. 너무 복잡함.
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
//실패하면 이거?
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
이를 reactor로 바꾸면?
userService.getFavorites(userId)
//detail들 가져옴. Flux<Details> 인 것 같음.
.flatMap(favoriteService::getDetails)
//만약 비었다면? suggestion을 가져옴.
.switchIfEmpty(suggestionService.getSuggestions())
//5개만?
.take(5)
//이 뒤 쪽은 다른 thread에서 처리하겠다는 뜻.(이 부분이 없으면 main thread가 이를 처리함)
.publishOn(UiUtils.uiThreadScheduler())
//보여줌.
.subscribe(uiList::show, UiUtils::errorPopup);
매우 간단해집니다.
stream이랑 비슷하다고 생각할 수 있습니다.
하지만 stream은 reactor와 달리 subscriber가 여러 개 있을 수 없다고 합니다.\
그 밖에도 backpressure 같은 기능을 제공해줍니다.
Future의 문제점은 get() 같은 함수를 호출하게 되면 그 부분에 blocking이 걸립니다.\
또한 lazy computation을 지원하지 않습니다.
이는 당장 필요하지 않는 부분은 나중에 계산 하는 것을 의미합니다.
예를 들면, JPA에서 프록시로 lazy fetch를 통해 그 값을 사용할 때 데이터를 가져옵니다.
그리고 a and b 같은 경우에는 a가 false인 경우에는 b를 계산하지 않습니다.
(future에서는 지원하지 않는다고 하는 이유는 모르겠습니다. 써본 적이 없어서....)
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join(); // 이 부분에서 다른 작업들이 끝날 떄 까지 기다림
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
reactor는 매우 깔끔합니다.
Flux<String> ids = ifhrIds();
Flux<String> combinations =
ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
return nameTask.zipWith(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList();
List<String> results = result.block(); //끝날 때 까지 기다림?
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);
flatMap vs flatMapSequentail vs concatMap
flatMap은 eagerly subscribing 이고, async입니다.
하지만 순서는 보장해주지 않습니다.
그리고 원소들을 즉시 반환합니다. 즉, subcriber의 작업이 끝나면 해당 원소를 바로 반환합니다.
flatMapSequentail은 flatMap에서 순서를 보장해줍니다.
concatMap은 앞의 두 개와 다르게 egaer하지 않습니다. 하나의 데이터가 들어오면, 데이터와 결과를 페어로 반환해줍니다.(똑같이 async입니다.)